一文了解 OS-中断
一步步认识中断
想要认识中断,我们必须要知道中断是什么,中断在操作系统中起到了什么作用,为什么中断是必不可少的。
我们先来看看操作系统与外部设备交互的过程,其中有两种交互方式,一种是直接通过汇编指令,另一种就是使用中断机制。
由于需要兼容多种底层设备,CPU 不方便直接去操作外部设备,因此需要加一个中间层——设备管理器(每一种外部设备都有一个设备控制器)来控制与外部设备的交互。设备管理器中包括了与 CPU 交互的三个主要的寄存器,状态寄存器、命令寄存器与数据寄存器以及与设备交互的控制电路,还有一个用于接收数据的缓冲区。其中状态寄存器存储了状态指示当前设备是否正在忙碌,或者处于就绪状态,命令寄存器存储了 CPU 需要执行的指令,数据寄存器存储了 CPU 传输给设备,或设备传入到设备控制器的数据。缓冲区用于接收和缓存数据,等待数据达到了缓冲区大小才将数据放入内存,避免了频繁占用总线开销大。
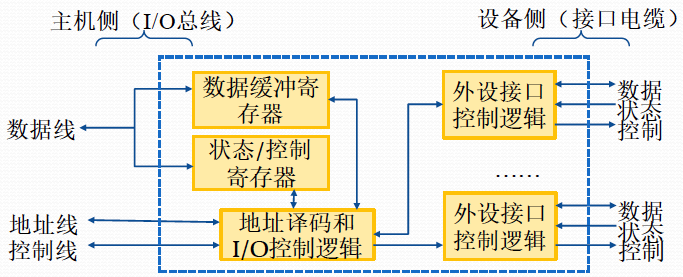
众所周知,CPU 的运算速度远远高于存储设备、外部硬件设备的操作速度(如网卡并不是一瞬间将所有数据都接收到,可能存在一个过程),CPU 需要去查看外部设备是否正在忙碌,此时使用的是轮询、忙等待的方式。
那么 CPU 如何知道设备控制器的三个寄存器在哪呢?
操作系统会给设备控制器的每个寄存器分配一个唯一的端口值,如 0X03A1,这被称为端口映射 IO。此外,还有一种将每个寄存器的地址看做内存地址的方式,这种情况可以直接通过 MOV 来传递数据,也被称为内存映射 IO。实际上,一台计算机中对于设备控制器的寄存器而言,内存映射 IO 和端口映射 IO 都有用到。
CPU 如何确定数据要传到哪个寄存器中呢?
当然是通过指令啦。在端口映射中,内存中有指令OUT 0X03A1 EAX,即代表将寄存器 EAX 的数据写入到 0X03A1 中,而在内存映射 IO 中,可以直接通过 MOV 将 EAX 数据 MOV 到对应目标地址。
CPU 轮询到外部设备为就绪状态时,即可将数据下发到数据寄存器中,并且设置设备的状态为忙碌(busy),再下发指令到命令寄存器中,执行指令,执行完成后再重置状态寄存器中的状态为就绪状态,这样就完成了一次与外部设备的交互。
说了那么多前置的知识,下面开始进入正题。
什么是中断
中断可以归结为一种事件处理机制,通过中断发出一个信号,然后操作系统会打断当前的操作,根据信号找到对应的处理程序处理这个中断,处理完毕之后再根据处理结果来决定是否需要返回到原程序继续执行。中断本质上是一种特殊电信号,且硬件设备生成中断的时候不与处理器时钟同步,因此中断随时可以产生,内核也随时可能因为新的中断的到来而被打断。这里我们主要讨论的是由硬件产生的异步中断,后面会讲述到。
中断解决了什么问题?
在上文中,我们讨论了当 CPU 需要访问外部设备时,它必须不断进行轮询和等待外部设备的状态。这种轮询过程极大地浪费资源,特别是在单核 CPU 中,由于设备访问的阻塞性质,CPU 可能无法响应其他程序的请求。为了解决这个问题,引入了中断的概念。中断机制有效地解决了 CPU 轮询和忙等待以检查外部设备状态所带来的性能损耗问题。
通过中断,当外部设备完成了需要 CPU 关注的任务,它会发送一个中断信号给 CPU。这时,CPU 就会立即暂停当前正在执行的任务,保存当前的状态,并转而去处理设备发来的中断。这样,CPU 就不再需要进行忙碌的轮询,而是在真正需要处理设备的时候再去响应它。举个🌰,操作系统现在与一台打印机交互,而这台打印机目前正在忙碌,所以 CPU 需要轮询发指令去检查打印机是否准备就绪。
我们再通过一个涉及键盘的示例来说明中断的整个过程:键盘上有一个键盘编码器,用于监控每个按键的状态。当用户按下一个按键时,键盘会解码数据并将其存储在键盘控制器的数据寄存器中。这将触发一个中断,并向中断控制器发送一个电信号(中断控制器是一个简单的电子芯片,通过复用技术将多个中断线路通过一个连接到 CPU 的管道进行通信)。
如果中断线处于活动状态,中断控制器会将中断转发给 CPU,并提供对应的中断号(IRQ)以表示特定键盘动作(每个中断都有唯一的标识)。CPU 查询中断向量表(其中存储了中断号与相应中断处理程序内存基地址的映射关系),然后跳转到指定的中断处理程序内存基地址以执行中断处理例程。
在这个过程中,CPU 需要保存之前程序的状态,包括寄存器信息、RIP、RSP、CPU 状态寄存器等。然后,通过类似于 IN EAX 0X03FA 的指令,CPU 将从外部设备(键盘)的数据寄存器读取数据到 EAX 寄存器中。然后,通过 OUT 0X06B1 EAX 指令,将 EAX 中的数据写入显示器的数据寄存器中,从而在显示器上显示数据。完成中断处理例程后,CPU 恢复到之前程序的状态。
中断机制解决了 CPU 轮询、忙等待的问题,CPU 与外部硬件交互的利用率可能还是很低
我们针对操作系统与打印机交互而言,操作系统每次执行OUT指令传递一个字符到打印机控制器中,此时如果打印机忙等,CPU 会去执行另一个用户程序,CPU 响应一次中断信号,切换到执行中断处理程序,然后再执行OUT指令传递一个字符到打印机控制器,如此反复。由于每次打印一个字符都要响应一次中断消耗 CPU 时间,主要的原因是CPU 参与了数据移动(将数据移动到打印控制器的数据寄存器)。
解决方法是使用 DMA 机制。DMA(Direct Memory Access)机制能显著减少 CPU 开销。DMA 控制器存储了数据源地址、数据目的地址、数据长度,当应用程序需要打印字符串时,CPU 通过系统调用陷入内核,设置 DMA 控制器,其余的工作就可以让 DMA 来完成,CPU 可以去执行其余的应用程序。当一次打印完成后,DMA 控制器通过中断控制器发出中断信号给 CPU,CPU 查表执行中断处理程序,只需要简单的切换回原先执行打印的应用程序即可。一次任务只需要一次中断,提高了 CPU 的利用率。
发起中断
对了,说到了中断时,CPU 需要执行操作系统中的指令(打印机的中断处理程序、设置 DMA),还需要讲讲系统调用、内核态与用户态,此处简单介绍一下。
操作系统由于安全问题,将 CPU 的执行状态分为了内核态与用户态,分别对应操作系统运行以及应用程序运行。在内核态下,CPU 可以使用所有的指令,而在用户态下,CPU 只能使用部分指令,这样确保了操作系统的安全。
在 Linux 中,系统调用是用户空间访问内核的唯一手段(除了异常和陷入以外)。系统调用为用户空间提供了一种硬件的抽象接口,且保证了系统的稳定和安全,系统调用时,内核可以基于权限、用户类型或其他规则对进行的访问进行裁决。
举个栗子,一个 c 语言写的应用程序,调用了printf()输出一些字符串,这个方法来自于用户接口程序库函数(glibc),其底层的实现就是调用了中断指令进行系统调用陷入内核。在 Linux32 位中,用户态通过调用INT $0X80中断指令陷入内核,在 Linux64 位中,调用的是 syscall 汇编指令,二者大体上是一样的。
应用程序如何通知内核执行系统调用呢?
通过软中断,告诉内核自己需要执行一个系统调用,希望系统切换到内核态,这样内核就可以代表应用程序在内核空间执行系统调用了。
CPU 怎么知道要执行哪个系统调用?
针对各个系统调用方法而言,操作系统为每个系统调用方法分配了一个唯一的系统调用号,内存中维护了一张系统调用表,存储了系统调用号以及系统调用的实现函数内存基地址(如 open 系统调用方法的实现函数为 sys_open)。用户态通过系统调用的方法名,找到记录在 glibc 中的系统调用号,然后将其存放在寄存器 EAX 中,查找中断向量表,执行中断处理程序,再查系统调用表,由于系统调用号存在寄存器 EAX 中,直接读取然后查询即可,然后执行实现函数。当然,大部分系统调用方法都会有参数,用户态在执行库函数的时候就会将参数放在特定的寄存器中(ebx,ecx,edx,esi,edi,ebp)
中断处理程序
中断处理程序只是普通的 c 函数,产生中断的每个设备都有一个相应的中断处理程序,包含在该设备的驱动程序中(如果一个设备可以产生多种不同的中断,那么这个设备就可以对应多个中断处理程序,该设备的驱动程序就需要准备多个中断处理函数)。中断处理函数与其余内核函数的区别在于,中断处理程序是用于被内核调用来响应中断的,运行在被称为中断上下文的特殊上下文中(偶尔也被称为原子上下文),该上下文中执行的代码不可阻塞。
由于中断随时都可能发生,需要保证中断处理程序能快速执行,且能快速恢复中断代码的执行,一般将中断处理的过程切成两部分。这样既解决了想要中断处理程序运行快,又想让中断处理程序完成的工作量多的矛盾关系。
中断处理程序是上半部(top half),接收到一个中断,它就立即开始执行,但是只做有严格时限的工作,如对接收的中断进行应答或复位硬件。允许稍后完成的工作都推迟到了下半部(bottom half),在合适的时机才会被执行。
我们以网卡为例,当网卡接收到来自网络的数据包时,需要通知内核数据包到了,网卡需要立即完成这件事,从而优化网络的吞吐量和传输周期,避免超时。因此网卡立即发出中断,内核通过执行网卡注册的中断处理程序来应答。中断开始执行,通知硬件,拷贝最新的网络数据包到内存,然后再去读取网卡更多的数据包。这些重要且急迫,又与硬件相关的工作都由上半部来完成。内核通常需要快速的拷贝网络数据包到系统内存,因为网卡上接收网络数据包的缓存大小固定,而且相比系统内存也要小得多。所以如果拷贝的动作延迟了,必然会导致缓存溢出,进入的网络包占满了网卡的缓存,后续到来的网络包只能被丢弃。当网络数据包被拷贝到系统内存后,中断的任务就完成了,此时它将控制权还给系统被中断前原先运行的程序,处理和操作数据包的工作都在随后的下半部来完成。
中断上下文
前面我们提到,中断上下文是中断处理程序的运行时环境,它与进程没有什么瓜葛,也与 current 当前宏无关(尽管 current 还是指向被中断的进程)。由于没有后备进程,中断上下文不可用休眠和重新调度。因此,也不能再中断上下文中调用某些函数(比如说sleep()函数)。
中断上下文有严格的时间限制,因为它打断了其他代码的执行,中断上下文中的代码应当迅速且简洁,尽量不使用循环处理繁重的工作。因为中断处理程序打断了其余程序的执行,这种异步执行的特性使得中断处理程序应该尽可能迅速、简洁。尽量将繁重的工作从中断处理程序中剥离出来,放到下半部来执行。
曾经中断处理程序没有自己的栈,它们共享所中断进程的内核栈,直到Linux2.6,添加了一个选项使得内核栈的大小从两页减少到一页(减轻内存的压力),为了应对栈大小的减少,中断处理程序拥有了自己的中断请求栈 hardirq_stack,每个 CPU 有一个,大小为一页,由于中断处理程序占了一整个页,能使用的空间比之前共享的还要大得多了(之前是共享中断进程内核栈的两个页,但是平均可用的栈空间很小)。其实中断栈的使用还是需要根据操作系统位数来讨论,在 64 位系统中,仍然是使用当前进程的内核栈作为中断栈,在 32 位系统中才使用 CPU 中单独的中断请求栈 hardirq_stack。中断处理程序不用关心内核栈大小为多少、栈如何设置,只要尽量节约内核栈空间即可。
异常与中断,傻傻分不清的系统调用
都说中断分为上下部,网络上很多文章说系统调用是通过软中断实现的,那么系统调用是中断吗?如果不是的话,为什么没有中断上半部呢?如果属于中断,那么执行的中断处理程序又是什么呢?软件中断又和软中断有什么关系呢?
前几天和朋友讨论时发现系统调用时发现了有这几个问题,究其原因是没有理清楚异常、中断的概念,还有过于僵化地认为中断必然会分为上半下半两部。
先说说异常,在《深入理解计算机系统》中提到,异常是异常控制流的一种,一部分由硬件实现,一部分由操作系统实现。异常是控制流中的突变,用于响应 CPU 状态中的某种变化,基本的思想是 CPU 状态的变化触发从应用程序到异常处理程序的突发的控制转移(异常),在异常处理程序处理完成后,将控制返回给被中断的程序或者终止。
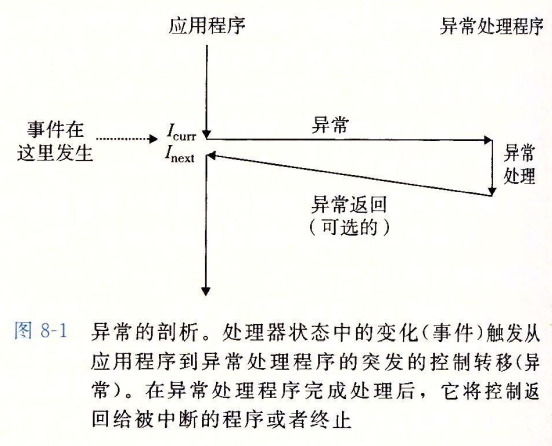
CPU 的状态变化的又被称为事件,事件可能与当前指令的执行有关,如发生虚拟内存缺页、算术溢出、除零等,也可能与当前指令的执行无关,如一个系统定时器产生信号或者一个 I/O 请求完成。
在任何情况下,当 CPU 检测到有事件发生时,就会通过一张异常表的跳转表执行一个间接过程调用(也称为异常),然后执行一个专门设计用于处理这类事件的操作系统子程序(异常处理程序)。当异常处理程序完成处理后,会根据引起事件的类型,以及处理事件的结果发生返回执行当前指令、返回执行下一条指令或者终止被中断程序这三种情况之一
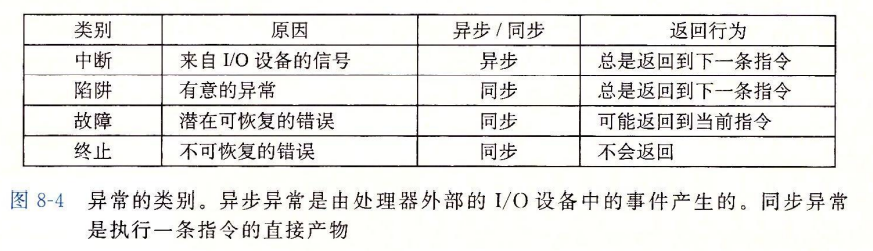
这个执行流程非常眼熟,简直就是中断的执行流程,那么我们来看看异常与中断的关系。在《深入理解计算机系统》,异常又被分为中断、陷阱(trap)、故障(fault)和终止(abort)四种。其中中断是异步产生的,是来自 CPU 外部的 I/O 设备的信号的结果,由于硬件中断不是由任何一条指令产生的,从这个意义上来说它是异步的(操作系统无法预知它的产生),而硬件中断的异常处理程序常常又被称为中断处理程序。
到这里差不多明了了,其实对于异常和中断来说,不同的书都有不同的定义,不过大致上都差不多。在《intel architectures software developer’s manual》中的定义是:
- An interrupt is an asynchronous event that is typically triggered by an I/O device.
- An exception is a synchronous event that is generated when the processor detects one or more predefined conditions while executing an instruction. The IA-32 architecture specifies three classes of exceptions: faults,traps, and aborts.
我们可以大致上把中断理解为是一个被外部I/O设备触发的异步事件,例如用户的键盘输入。它是一种电信号,由硬件设备生成,然后通过中断控制器传递给 CPU,CPU 有两个特殊的引脚 NMI 和 INTR 负责接收中断信号。
而异常则是一个同步的事件,通常由程序的错误产生的,或是由内核必须处理的异常条件产生的,如缺页异常或 syscall 等。异常可以分为错误、陷阱、终止。同步的意思是它产生时必须考虑与处理器时钟同步,只有在一条指令执行完毕后 CPU 才会发出中断,而不是在代码指令执行期间发生的,比如说系统调用。
来看看陷阱(trap),陷阱是有意的异常,是执行一条指令的结果。它最重要的用户就是在用户程序和内核之间提供一个像过程一样的接口,叫系统调用。系统调用与普通的函数调用的实现不同,普通函数调用允许在用户模式,被限制了函数可以执行的指令的类型,且它们只能访问与调用函数相同的栈,而系统调用允许在内核模式中,内核模式允许系统调用执行特权指令,并访问定义在内核中的栈。
实际上,系统调用的执行过程是通过中断实现的,使用到的中断属于“软件触发的硬中断” ,属于陷阱(异常),即同步中断,而不是本文提到的中断(硬件中断),因为系统调用过程是要同步处理的,不能使用异步的软中断方式实现。系统调用通过指令触发异常(这里的异常是一个过程,实际上就是同步中断,从应用程序被打断,陷入内核态,执行完后又恢复回来。对于异常的几种子类而言,基本都是这个流程),陷入内核态,触发异常处理程序(在异步中断中也叫中断处理程序),这个异常处理程序的内容就是进行系统调用(通过在 EAX 寄存器获取系统调用号,查系统调用表得到系统调用实现方法的基地址,执行系统调用方法),执行完异常处理程序后恢复到被中断执行的指令。
在 linux 中执行 cat /proc/interrupts 会打印所有注册的硬中断,仔细观察之后,你会发现其中包含一个名为‘CAL’的中断,它就是系统调用所对应的中断号。这是通过执行机器指令触发的,所以我才说它是软件触发的硬中断。
1 | cat /proc/interrupts |
总结一下,我们可以把异常称为同步中断,而本文所说的硬件中断称为异步中断。异步中断的实现是分为上半部与下半部的,但也不是所有的异步中断都需要有下半部,只有需要推迟执行的任务才需要下半部(用另一种情况说,理想情况下,只有下半部),而系统调用属于同步中断,通过异常来触发软中断,执行的中断处理程序就是系统调用。而软件中断,我没找到比较合理的定义,网络上基本都是将中断分为硬件中断与软件中断,软件中断由软件触发,即指令触发,这么说来软件中断也是属于同步中断,可以理解为系统调用也是属于软件中断的一种。需要明确的是,软中断并不是软件中断,软中断只是中断下半部的一种实现机制,是异步中断的一部分,用于执行推迟的工作。
软中断
软中断的意义是使内核可以延期执行任务,因为它的运作方式和上述的中断类似,但完全是从软件实现的,所以称为软中断。内核借助软中断来获知异常情况的发生,而该情况将在稍后有专门的处理程序解决。
软中断是相对稀缺的资源,因为每个软中断都有一个唯一的编号,所以使用其必须谨慎,不能由各种设备驱动程序和内核组件随意使用。默认情况下,系统上只能使用 32 个软中断,但这没什么,因为基于软中断内核还衍生出了许多其他其他延期执行机制,比如 tasklet、工作队列和内核定时器。我们稍后会介绍它们。
只有中枢的内核代码才会使用到软中断,软中断只用于少数场景,如下就是其中相对重要的场景。其中两个用来实现 tasklet(HI_SOFTIRQ,TASKLET_SOFTIRQ),两个用于网络的发送和接收(NET_TX_SOFTIRQ,NET_RX_SOFTIRQ,这两个是构建软中断机制的最主要原因)一个用于块层,实现异步请求完成(BLOCK_SOFTIRQ),一个用于调度器(SCHED_SOFTIRQ),以实现 SMP 系统上周期性的负载均衡。在启用高分辨率定时器时,还需要一个软中断(HRTIMER_SOFTIRQ)。
1 | enum |
软中断的编号形成了优先顺序,这影响了多个软中断同时处理时执行的次序。
我们可以通过raise_softirq(int nr)发起一个软中断(类似普通中断),软中断的编号通过参数指定。每个 CPU 都有一个位图irg_stat,其中每一位都代表了一个中断号,raise_softirq()会设置各个 CPU 变量irg_stat的比特位。该函数会将对应的软中断标记为 1,但是该中断的处理程序不会立即运行。通过使用特定于处理器的位图,内核可以确保几个软中断(甚至是相同的)可以在不同的 CPU 上执行。
那么软中断什么时候执行呢?
- 当前面的硬件中断处理程序执行结束后,会检查当前 CPU 是否有待处理的软中断,如果有的话会按照次序处理所有的待处理软中断,每处理一个软中断之前,会将其对应的比特位清零,处理完所有软中断的过程,我们称之为一轮循环。
- 一轮循环处理结束后,内核会通过位图再次检查是否有新的软中断到来,如果有的话会一并处理,这就会出现第二轮循环,第三轮循环。
- 但是软中断不会无休止的重复下去,当处理轮数超过
MAX_SOFTIRQ_RESTART(通常是 10),就会唤醒软中断守护线程(每个 CPU 都有一个),然后退出。
- 软中断守护线程负责在软中断过多时,以一个调度实体的形式(即能合其他进程一样被调度),帮助处理软中断请求,在这个守护线程中会重复的检测是否有待处理的软中断请求。
- 如果没有软中断请求了,则会进入睡眠状态,等待下一次被唤醒。
- 如果有请求,则会调用对应的软中断处理程序
下半部
下半部执行与中断处理密切相关但中断处理程序本身不执行的工作,在理想的情况下,最好是中断处理程序将所有的工作都交给下半部分执行,因为我们希望中断处理程序执行工作越快越好,但是中断处理程序注定要完成一部分的工作,比如通过操作硬件对中断的到达进行确认,或者从硬件拷贝数据,这些工作对时间非常敏感,只能靠中断处理程序自己完成。
在上半部将数据从硬件拷贝到内存后,那么应当在下半部来处理它们。操作系统没有规定哪些任务在哪些阶段来执行,需要开发者自己把握分寸,将中断处理程序执行的时间尽量压缩到最小。
对于上半部来说,中断处理程序执行的过程中,当前的中断线上的所有处理器都会被屏蔽,下半部的执行则不会,在下半部执行的过程中,允许响应所有的中断,这样提高了系统的响应能力,不止是 Linux,这也是大部分操作系统的设计实现。
与上半部只能通过中断处理程序实现不同,下半部可以通过多种机制实现,在 Linux 的发展中就存在多种的下半部机制。虽然软中断是将操作推迟到未来时刻执行的最有效方式,但是软中断的中断号有限,而且该延期机制处理起来非常复杂。因为多个处理器可以同时且独立地处理软中断,所以一个软中断的处理程序例程可以在几个 CPU 上同时运行,这要求软中断处理程序必须是可重入且线程安全的,临界区必须使用自旋锁来保护。此外,在软中断中还不能进入睡眠,在中断上下文中我们提到过,软中断的其中一部分是硬件中断处理结束后才进行的,这时候软中断执行函数没有调度实体,所以不能进入睡眠。
早期的下半部机制称为 BH,它提供了一个静态创建、由 32 个 bottom halves 组成的链表,上半部通过一个 32 位的整数中的一位来标识出哪个 bottom half 可以执行,每个 BH 在全局范围内进行同步。即使分属于不同的处理器,也不允许任意两个 bottom half 同时执行。这种机制虽然方便且简单,但是不够灵活,而且有性能瓶颈。
后续出现了任务队列机制来实现工作的推后执行,试图用它来替代 BH 机制。内核定义了一组队列,每个队列都包含一个由等待调用的函数组成的链表。根据其在所处队列的位置,这些函数会在某个时刻执行,但是它还是不够灵活,不能胜任一些性能要求比较高的子系统,如网络部分。
为了弥补这个缺点,Linux2.3 中引入了软中断和 tasklet,如果不考虑兼容,软中断与 tasklet 完全可以替代 BH 机制。软中断也是一组静态定义的下半部接口,有 32 个,即使是相同类型的两个接口,也可以在处理器上同时执行。tasklet是一种基于软中断实现的灵活性较强的、动态创建的下半部实现机制,相同类型的 tasklet 不能同时执行。实际上,tasklet 其实是一种性能与易用性之间寻求平衡的产物,对于大部分的下半部处理只用 tasklet 就够了,只有像网络这种要求性能高的子系统才需要使用软中断。软中断必须再编译期间就进行静态注册(驱动处理程序),而 tasklet 可以通过代码动态注册。
网络上很多文章将所有的下半部都当做软件产生的中断,或者软中断,其实软中断与 BH 和 tasklet 并驾齐名,在 Linux2.5 中,BH 机制和任务队列机制都被完全去除了。新引入的工作队列的接口取代了任务队列的接口,在工作队列中,它们需要先对推后执行的工作进行排队,稍后才在进程上下文中执行它们。
| 下半部机制 | 状态 |
|---|---|
| BH | 在 2.5 中去除 |
| 任务队列(task queues) | 在 2.5 中去除 |
| 软中断(softirq) | 在 2.3 开始引入 |
| tasklet | 在 2.3 开始引入 |
| 工作队列(work queues) | 在 2.5 开始引入 |
tasklet
tasklet 的实现基于软中断,但是它们更易于使用,因而更适合于设备驱动程序。
在内核中,每个 tasklet 都有与之对应的一个对象表示,内核以链表的形式管理所有的 tasklet,而且每个 tasklet 都有两个状态,这两个状态通过 state 字段的不同位表示,其中一个代表 tasklet 是否注册到内核,成为一个调度实体(TASKLET_STATE_SCHED),另一个代表该 tasklet 是否正在运行(TASKLET_STATE_RUN)。通过 TASKLET_STATE_RUN,我们可以使一个 tasklet 只在一个 CPU 上执行。此外 count 字段大于 0 表示该 tasklet 被忽略。
1 | struct tasklet_struct |
当我们注册 tasklet 时,如果发现 TASKLET_STATE_SCHED 已经被置为 1,则说明该 tasklet 已经注册了,就不会重复注册。那么 tasklet 说明时候执行呢?tasklet 的执行被关联到 TASKELT_SOFTIRQ 软中断。因此,在调用raise_softirq(TASKLET_SOFTIRQ)时,tasklet 就会在合适的时机执行。执行过程如下:
- 检查 tasklet 的 TASKLET_STATE_RUN 是否被置为 1,是的话则说明其他 CPU 在执行它,那么当前 CPU 就会跳过它。
- 检查其是否被禁用(count 是否大于 0)
- 将 TASKLET_STATE_RUN 置为 1
- 调用 tasklet 的 func
因为 tasklet 本质上是再软中断的处理程序中执行的,所以它也不能睡眠或阻塞,但是它可以保证同一时刻某个 tasklet 只会在一个 CPU 上执行,有着天生的线程安全保障。
除了普通的 tasklet 之外,内核还提供了另一种 tasklet,它具有更高的优先级。高优先级的 tasklet 通过 HI_SOFTIRQ 软中断触发而不是 TASKLET_SOFTIRQ,这两种 tasklet 在不同的链表中维护。这里的高优先级指的是软中断的处理程序 HI_SOFTIRQ 比其他软中断处理程序更先执行,因为它排在软中断号的第一位。很多声卡驱动以及高速网卡都是依赖高优先级的 tasklet 实现的。
等待队列
我们已经得知 tasklet 无法睡眠和阻塞,那么当设备驱动要等待某一特定事件发生的时候,有什么办法吗?我们可以通过等待队列来完成这个需求。既然要睡眠和阻塞,肯定需要一个调度实体,换句话说,等待队列中的项不再是一个简单的处理函数,而是一个类似于后台进程一样的存在。
1 | struct wait_queue_t { |
等待队列的使用分为如下部分
- 为了使当前进程在一个等待队列中睡眠,那么需要调用
wait_event()函数。进程进入睡眠后,会将控制权释放给调度器。内核通常会在向块设备发出传输数据的请求后,调用该函数,因为传输操作不会立即发生,而在此期间有没有其他事情可做,所以进程可以睡眠,将 CPU 时间让给系统中的其他进程。 - 就上面的例子而言,块设备的数据到达后,必须调用
wake_up()函数来唤醒等待队列中的睡眠进程。在使用wait_event()使进程睡眠之后,必须确保在内核中另一处有一个对应的wake_up()调用。
wait_event()是一个宏,它接收两个参数,第一个是等待队列对象 wait_queue_t,第二个是判断事件是否到来的 bool 表达式。这个宏的实现也很简单,就是先将当前进程加入到等待队列的 task_struct 链表中,然后循环地通过第二个参数确认事件是否到来,如果到来了则跳出循环,否则继续睡眠。
wait_up()函数的实现也很简单,有三个参数,第一个是等待队列链表的第一个对象 wait_queue_head_t,第二个参数 mode 指定进程的状态(TASK_UNINTERRUPTIBLE | TASK_INTERRUPTIBLE),第三个参数 nr_exclusive 控制唤醒该队列上的几个进程,如果为 1 则表明是独占的事件,只唤醒其中一个,如果是 0 则唤醒该队列中的所有进程。
工作队列
工作队列是将任务延迟执行的另一种机制。它和等待队列一样是通过守护进程实现的,在用户上下文执行,所以可以睡眠任意长的时间。它与“线程池”非常类似,在创建的时候我们需要指定线程名,同时也可以指定是单个线程,还是每个 CPU 上创建一个对应的线程。
1 | struct workqueue_struct *__create_workqueue(const char *name,int singlethread) |
创建好工作队列后,我们可以向其中注册任务,每个任务的结构如下。注册完的的任务会维护在一个链表中,按照顺序依次执行。
1 | struct work_struct { |
而且在注册工作内容时,我们还可以指定延时任务,它会在一个指定延迟后开始执行。当创建延时任务后,内核会创建一个定时器,它将在 delay jiffies 之后超时,随后相关的处理程序就会将 delayed_word 内部的 work_struct 对象加入到工作队列的链表中,剩下的工作就和普通任务完全一样了。
1 | int fastcall queue_delayed_work(struct workqueue_struct *wq,struct delayed_work *dwork,unsigned long delay) |
总结
到此为止,本文介绍了中断的执行流程、中断的意义、中断的划分以及划分后部分的执行内容和机制。除此之外,中断还有很多地方可以深入探索,譬如详细叙述异常以及异常的其余分类、中断处理程序的初始化、加载、释放过程,中断机制下半部机制的选择,对于下半部机制的执行过程中,还涉及到内核同步与并发等。对于本文而言,仅仅是简要介绍中断的一部分。
参考与推荐阅读
- 抖码课堂
- 《Linux 内核设计与实现》
- 《深入理解计算机系统》
- 计算机系统中的异常 & 中断
- Linux 中断 推荐阅读








